
Map Alignment#
The pyOpenMS map alignment algorithms transform different maps (peak maps, feature maps) to a common retention time axis. Because chromatographic columns are less stable, retention times of identical compounds can vary across runs. To correct for RT drift, map alignment attempts to find common landmarks across runs and adjusts the RT of all features to minimize the distance of landmarks across feature maps (runs).
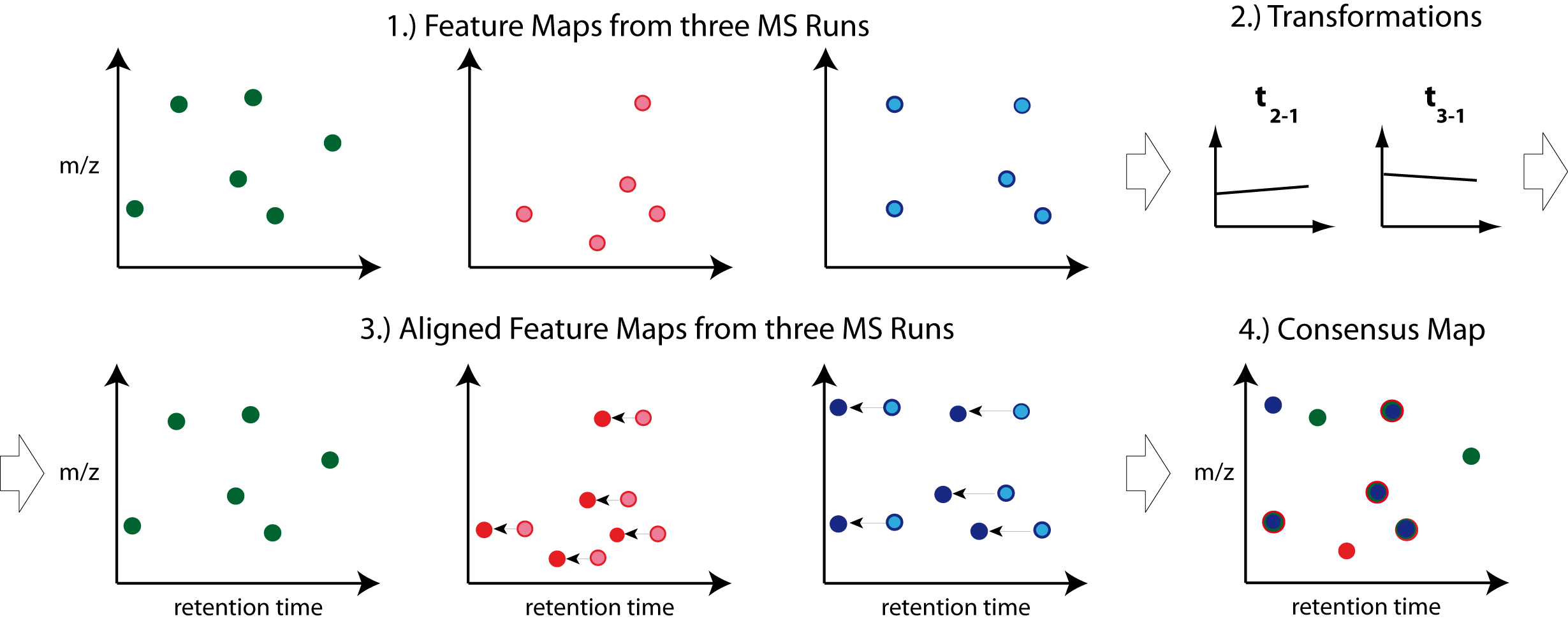
Note: Creating a consensus map from the aligned maps is performed by a feature linking algorithm (see next chapter).
Different map alignment algorithms are available in pyOpenMS:
If you want to apply a custom RT mapping, you can use:
To perform a simple linear alignment (an affine transformation to be exact, i.e. an offset and a slope) we can employ the algorithm MapAlignmentAlgorithmPoseClustering.
This algorithm in OpenMS can also align peak maps, but we usually recommend aligning on the feature level, since
it’s much faster (less features than peaks) and also more stable.
Other map alignment algorithms in pyOpenMS require the input data to have PSMs annotated. See Annotating PSMs to features on how to do that.
Also, some require (or support) a reference map (the one which all the other feature maps align to). More on this below.
All algorithms except MapAlignmentAlgorithmPoseClustering can correct the RT using a variety of models/functions fitted to the landmarks used across feature maps.
Here is a summary table:
algorithm |
input type |
transformation in RT |
uses & requires PSMs |
reference map |
|---|---|---|---|---|
feature maps or peak maps |
linear (affine transformation) |
no |
required |
|
peak map, feature maps, IDs |
any [1] |
yes |
optional |
|
feature maps |
any [1] |
yes |
not supported/needed |
You should pick the algorithm which does not overfit your data and maximizes the number of complete consensus features during a later feature linking stage.
Download Example Data#
1import pyopenms as oms
2from urllib.request import urlretrieve
3
4base_url = (
5 "https://raw.githubusercontent.com/OpenMS/OpenMS/develop/doc/pyopenms/src/data/"
6)
7
8# we use featureXML files which already contain PSMs (as obtained by oms.IDMapper())
9# ... so we can use all aligners pyOpenMS has to offer
10feature_files = [
11 "BSA1_F1_idmapped.featureXML",
12 "BSA2_F1_idmapped.featureXML",
13 "BSA3_F1_idmapped.featureXML",
14]
15
16feature_maps = []
17
18# download the feature files and store feature maps in list (feature_maps)
19for feature_file in feature_files:
20 urlretrieve(base_url + feature_file, feature_file)
21 feature_map = oms.FeatureMap()
22 oms.FeatureXMLFile().load(feature_file, feature_map)
23 feature_maps.append(feature_map)
Selecting a Reference Map#
Some alignment algorithms in pyOpenMS require to set a reference, e.g. MapAlignmentAlgorithmPoseClustering.
For others, it is optional, e.g., MapAlignmentAlgorithmIdentification.
Finally, MapAlignmentAlgorithmKD is reference-free by definition.
For MapAlignmentAlgorithmPoseClustering we could pick the feature map with the largest number of features as a reference,
to provide the maximum number of reference points.
The retention times of the other feature maps are aligned to this.
1# set ref_index to feature map index with largest number of features
2ref_index = [
3 i[0]
4 for i in sorted(
5 enumerate([fm.size() for fm in feature_maps]), key=lambda x: x[1]
6 )
7][-1]
8
9aligner = oms.MapAlignmentAlgorithmPoseClustering()
10aligner.setReference(feature_maps[ref_index])
11
12## push all maps except the reference into the align method; don't align the reference to itself for max. efficiency
13feature_maps_to_align = feature_maps[:ref_index] + feature_maps[ref_index+1:]
Map Alignment Algorithm#
Now, let’s run an algorithm. Since the interfaces of the aligners differ slightly, we will go though them one by one, starting with MapAlignmentAlgorithmPoseClustering.
1aligner = oms.MapAlignmentAlgorithmPoseClustering()
2aligner.setReference(feature_maps[ref_index])
3
4
5## change default params, if you want ...
6p = aligner.getParameters()
7# p.setValue(...)
8aligner.setParameters(p)
9
10# perform alignment and transformation of feature maps to the reference map (exclude reference map)
11for feature_map in feature_maps_to_align:
12 trafo = oms.TransformationDescription()
13 aligner.align(feature_map, trafo)
14 transformer = oms.MapAlignmentTransformer()
15 transformer.transformRetentionTimes(
16 feature_map, trafo, True
17 ) # store original RT as meta value in `feature_map`
The interface of MapAlignmentAlgorithmIdentification is a bit different, so have to adapt our code a bit.
In contrast to MapAlignmentAlgorithmPoseClustering, which always fits a linear model, we can choose which model to fit to the landmarks found by the algorithm. Our choices are “linear”,”b_spline”,”lowess” and “interpolated”.
1aligner = oms.MapAlignmentAlgorithmIdentification()
2## we could set a reference map; but we don't. Instead, we rely on the algorithm to use an internal average of all maps
3ref_index = -1 # -1 means 'take the median' for this algorithm
4
5## let's change some default parameters of MapAlignmentAlgorithmIdentification, just to see how it's done:
6p = aligner.getParameters()
7p.setValue("max_rt_shift", 0.2) # 20% of total RT span
8p.setValue("use_feature_rt", "true")
9aligner.setParameters(p)
10
11## this list will be filled with transformations; you could use them to transform the original mzML, for example
12trafos = list()
13aligner.align(feature_maps, trafos, ref_index)
14
15# the transformations now contain the landmarks, but we still need to compute (fit) a model to them,
16# ... before applying it to the feature maps:
17# Possible models are: "linear","b_spline","lowess","interpolated"
18for fm, trafo in zip(feature_maps, trafos):
19 trafo.fitModel("linear")
20 transformer = oms.MapAlignmentTransformer()
21 transformer.transformRetentionTimes(
22 fm, trafo, True
23 ) # stores original RT as meta value 'original_RT' for each feature in each `feature_map`
You can test different models, but since we only have very few data points in our toy example, the linear model works best.
Visualization#
Plotting feature maps before and after alignment. We should observe that the data points cluster closer together:
1import matplotlib.pyplot as plt
2import numpy as np
3
4def plot_consensus_maps(fmaps):
5 """
6 Plots consensus maps before and after alignment.
7
8 Parameters:
9 - fmaps: List of FeatureMaps.
10 """
11 fig, axes = plt.subplots(1, 2, figsize=(10, 5))
12
13 titles = ["consensus map before alignment", "consensus map after alignment"]
14 x_labels = ["RT", "RT"]
15 y_label = "m/z"
16
17 for i, ax in enumerate(axes):
18 ax.set_title(titles[i])
19 ax.set_xlabel(x_labels[i])
20 if i == 0: ax.set_ylabel(y_label)
21
22 for fm in fmaps:
23 x_data = [f.getMetaValue("original_RT") if i == 0 else f.getRT() for f in fm]
24 y_data = [f.getMZ() for f in fm]
25 alpha_values = np.asarray([f.getIntensity() for f in fm]) / max([f.getIntensity() for f in fm])
26 ax.scatter(x_data, y_data, alpha=alpha_values)
27
28 fig.tight_layout()
29 fig.legend(
30 [fmap.getDataProcessing()[0].getMetaValue("parameter: out")[:-11] for fmap in fmaps],
31 loc="lower center",
32 )
33 plt.show()
34
35# Example usage:
36plot_consensus_maps(feature_maps)

We can also inspect the underlying transformation and the landmarks it is based upon:
1def plot_transformed_rt_with_trafo(fmaps, trafos):
2 """
3 Plots original RT vs. transformed RT for each feature map and ensures matching colors for transformation points.
4
5 Parameters:
6 - fmaps: List of FeatureMaps that have been aligned.
7 - trafos: List of Transformations applied to the FeatureMaps.
8 """
9 fig, ax = plt.subplots(figsize=(8, 5))
10
11 ax.set_title("RT Transformation Before vs. After Alignment")
12 ax.set_xlabel("Original RT")
13 ax.set_ylabel("Transformed RT")
14
15 colors = plt.cm.viridis(np.linspace(0, 1, len(fmaps))) # Generate distinct colors for each map
16
17 for i, (fm, trafo) in enumerate(zip(fmaps, trafos)):
18 label = fm.getDataProcessing()[0].getMetaValue("parameter: out")[:-11]
19
20 # Extract original and transformed RTs from feature maps
21 original_rt = [f.getMetaValue("original_RT") for f in fm]
22 transformed_rt = [f.getRT() for f in fm]
23
24 # Plot feature map RTs
25 ax.scatter(original_rt, transformed_rt, alpha=0.5, s=20, color=colors[i], label=f"{label} - Features")
26
27 # Extract transformation points
28 trafo_points = trafo.getDataPoints()
29 original_trafo_rt = [point.first for point in trafo_points]
30 transformed_trafo_rt = [point.second for point in trafo_points]
31
32 # Plot transformation points
33 ax.scatter(original_trafo_rt, transformed_trafo_rt, marker="D", s=100, edgecolors="black", color=colors[i],
34 label=f"{label} - Trafo")
35
36 ax.legend(loc="upper left")
37 ax.grid(True)
38 plt.show()
39
40# Example usage:
41plot_transformed_rt_with_trafo(feature_maps, trafos)
While we do not know the underlying features using just this information, we can see that features in corresponding maps are now nicely aligned horizontally (the new RT). Also, it seems a linear model nicely fits all the data points in each feature map. More flexible models (e.g., LOWESS) may overfit and degrade performance—feel; free to experiment.
